
티스토리 뷰
컴퓨터의 메모리
Capacity, Access time, Cost(per bit)
현재의 메모리는 (SRAM의 장점) 빠르다+ (DRAM의 장점) 크고 싸다가 목표이다.
메모리 계층 구조(memory hiearchy)
이 구조의 목표는 프로세서가 메모리 접근을 빠르게 할 수 있도록 최적화하는 것입니다.
상위 계층은 빠르고 비싸고, 하위 계층은 느리고 저렴함,

프로세서가 직접 접근하는 순서:
레지스터(Register) – CPU 내부에 있으며 가장 빠름.
캐시 메모리(Cache Memory) – 레지스터보다 느리지만, 매우 빠른 속도를 가짐.
주 기억장치(Main Memory, RAM) – 캐시보다 느리지만 하드 디스크보다는 빠름.
디스크 메모리(Disk Memory, HDD/SSD) – 용량이 크지만 속도가 가장 느림.
프로세서는 속도를 높이기 위해 낮은 레벨(예: 디스크)보다는 높은 레벨(예: 캐시 메모리)에 접근하는 것이 이상적입니 다. 디스크 접근을 최소화하는 것이 성능 최적화의 핵심!
그럼 어떻게 낮은 레벨(디스크)에 접근하는 것을 최소화 할 것인가?
자주 사용되는 데이터를 상위 계층(빠른 메모리)에 저장하는 전략이 필요
참조의 지역성:
시간적 지역성은 최근 참조된 데이터가 다시 참조될 가능성이 높다
공간적 지역성은 인접한 데이터가 함께 참조될 가능성이 높다
평균접근시간(Average Acess Time)
hit - 상위계층 메모리에서 발견될 때
miss - 하위계층 메모리에서만 발견되는 경우(1-hit rate)
Hit rate(히트율)보다 Miss rate(미스율)이 더 직관적이고 유용


cache memory(캐시메모리)
필요한 이유:
프로세서는 명령어를 실행할 때 여러번 (최소 한 번 이상) 메모리에 접근해야 한다.(지속적으로 메모리에 접근)
프로세서속도가 메모리 속도 보다 빠르다.
그래서? :
참조의 지역성원리를 사용하여, 작고빠른 메모리인 캐시를 사용한다. 자주 참조되는 메모리 블럭을 캐시에 저장한다.
>> 캐시메모리는 시스템 성능을 향상시키는 중요한 요소!
cache organization
시간적 지역성 : 자주 참조하는 명령어와 데이터 값
공간적 지역성 : 앞으로 필요할 것으로 예상되는 데이터에 캐시를 가져올 때 더 많은 연속데이터

cache design
연관도, 블럭사이즈, 캐시 사이즈

Cache Read Operation
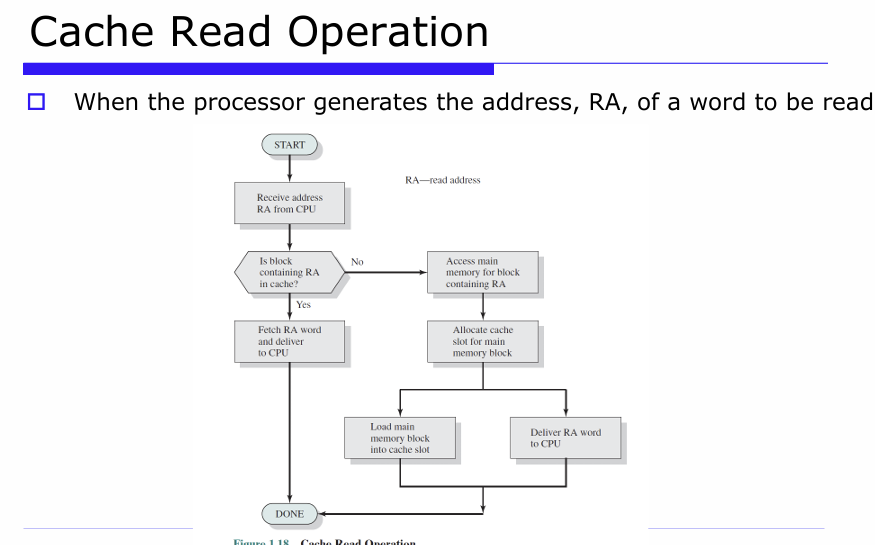
1. CPU가 데이터를 읽으려고 주소(RA, Read Address)를 보냄.
2. 캐시에 해당 주소의 데이터가 있는지 확인 : [Yes (캐시hit) : 바로 데이터를 CPU에 전달하고 끝! (빠름)] /[ No (캐시 miss) : 메인 메모리에서 가져오는 단계로 진행 ]
3. 메인 메모리에서 주소 RA가 포함된 블록을 읽어옴
4. 가져온 블록을 저장할 캐시 공간을 확보함
5. 메인 메모리에서 가져온 블록을 캐시에 저장
6. CPU가 요청한 RA 주소의 데이터를 CPU에 전달
7. 모든 과정이 끝나고, CPU는 데이터를 받음
Cache Write Operation
CPU가 어떤 데이터를 쓰기(write) 하려고 할 때, 그 데이터가 캐시에 있는지 여부에 따라 처리 방식이 달라져
1. Write-Hit (쓰기 히트) → 캐시에 이미 그 데이터 블록이 있음
Write-through (쓰기 관통) : 캐시에 쓰면서 동시에 메인 메모리에도 바로 씀, 메모리랑 캐시 데이터가 항상 동기화됨 (장점)
Write-back (지연 쓰기) : 일단 캐시에만 쓰고, 나중에 그 블록이 캐시에서 쫓겨날 때 메모리에 씀 , Dirty bit 필요 (캐시와 메모리 내용이 달라졌는지 표시) , 쓰기 횟수 줄어들어 성능 좋음(장점)
2. Write-Miss (쓰기 미스) → 캐시에 해당 데이터가 없음
Write-allocate (쓰기 할당) : 메인 메모리에서 블록을 캐시로 불러온 뒤 캐시에 씀, 장점: 그 위치에 반복적으로 쓸 거면 효율적
가장 많이 쓰는 방법
Write-back + Write-allocate
쓰기 성능이 좋고, 반복적인 쓰기에도 효율적이기 때문이야.
I/O Communication Techniques
I/O 모듈은 컴퓨터 시스템과 외부 세계(외부 장치들)를 연결
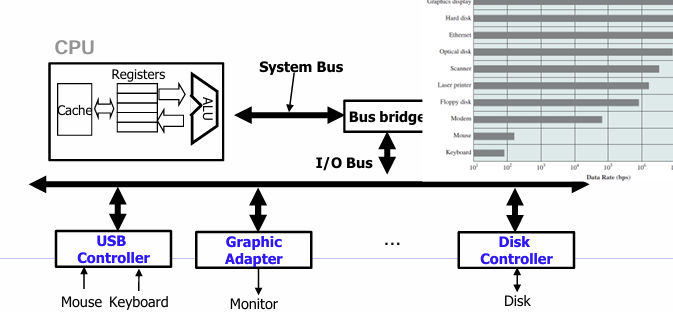
Bus (버스):
CPU, 메모리, I/O 장치를 연결해주는 고속 통로
주소(address), 데이터(data), 제어(control) 신호를 전송하는 선들의 모음
데이터를 일정 크기로 묶어서 전송하는데, 이 묶음을 word(워드) : 기본적인 시스템 파라미터 (시스템이 설계될 때 정해짐)
1. Bus Bridge (버스 브리지) : 브리지는 버스 간의 번역기 역할
2. Bus Architecture 구성 : I/O Bus는 속도가 느림
CPU <== System Bus ==> Bus Bridge <== Memory Bus ==> Main Memory
||
I/O Bus
↓
I/O Modules (ex. Disk, Mouse)
Device Controller 정리
1. Controller(제어기)란?
모든 I/O 장치는 I/O 버스를 통해 Controller(또는 Adapter) 에 연결
2. 장치마다 데이터 속도와 기능이 다름

Bus Transaction (버스 전송)
읽기(Read) 또는 쓰기(Write) 작업을 하기 위한 일련의 단계
1. Bus Master (버스 마스터) : 보통 CPU ,주도하는 장치
2. Bus Slave (버스 슬레이브) : 명령을 수신하고 수행하는 장치 (예: 메모리)
3. Bus Arbiter (버스 중재기) : 여러 요청이 들어올 때 순서를 결정하는 장치
Accessing Memory
데이터를 저장하고 불러오기 위해 메모리(RAM)사용

1. CPU는 주소A를 시스템 버스에 넣고, 메인메모리는 그것을 읽고 데이터단어가 올때까지 기다린다.
2. CPU가 데이터단어 y를 보낸다.
3. 메인메모리는 y를 버스로부터 읽고, A의 주소를 저장한다.
(movq %rax,A) : %rax의 값을 메모리 주소A에 저장.
: Programmed I/O
CPU가 (device로 부터)직접 I/O장치와 데이터를 주고 받는 형식 (가장 old한 방식)
1. CPU가 I/O장치에 읽기 명령을 지시한다.
2. CPU는 polling(풀링)을 통해 반복적으로/주기적으로 상태 레지스터를 확인한다. ( I/O장치 -> CPU)
3. I/O장치가 준비가 되면, CPU는 I/O장치에서 데이터를 읽는다. ( I/O장치 -> CPU)
4. CPU는 메모리로 데이터를 저장한다.
단점 : a time comsuming process (풀링으로 인한 자원낭비)
: Interrupt - Driven I/O
1. CPU는 I/O장치에 명령을 내리고, 다른유용한작업을 하러간다.(폴링과 다른점)
2. I/O장치가 준비가 되면, 컨트롤러는 CPU에 인터럽트 신호를 보낸다.
3. CPU는 현재작업을 중단하고, 인터럽트 핸들러를 실행시킨다.
4. CPU는 메모리로 데이터를 저장한다.
단점 : 여전히 CPU의 적극적인 개입을 필요로한다.
: DMA(Direct Memory Access) ★
CPU가 개입하지 않고, I/O가 직접 메모리와 데이터를 주고 받는 방식, 고속데이터 전송이 가능하다.

1. CPU는 명령어(소스/목적지 주소 및 바이트 수)를 작성하여 I/O 작업을 시작합니다.
2. I/O 컨트롤러가 장치를 읽고 주 메모리로 직접 메모리 액세스(DMA) 전송을 수행합니다.
3. DMA 전송이 완료되면 컨트롤러는 CPU에 인터럽트를 알립니다.
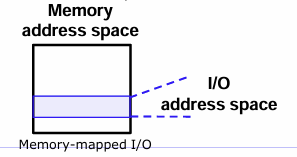
: I/O Address Space
I/O 장치들도 주소(Port) 를 가짐 → 이 주소를 통해 CPU와 데이터를 주고받음 / 이주소를 다루는 방식에는 두가지가 있다.
1. Port- mapped I/O
: I/O 장치 주소 공간이 메모리와 분리되어 있음, 특수한 명령어 사용 (예: in, out in x86) , 단순하지만 유연성은 떨어짐
2. Memory-mapped I/O
: I/O 장치가 메모리 주소 공간 일부를 공유함, 일반 메모리 명령어(load/store) 로 접근 가능!
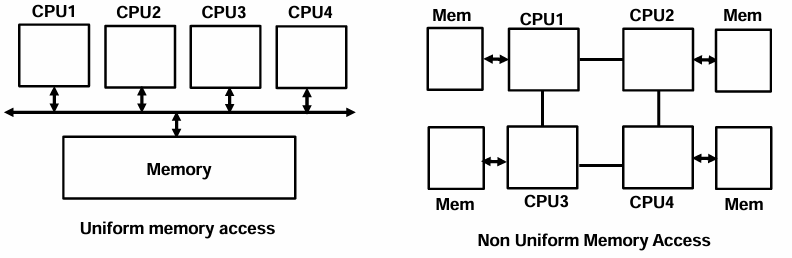
Multiprocessor and Multicore Organization
CPU(프로세서)가 2개 이상 있는 컴퓨터 시스템
: Multi-processor systems
1. Asymmetric multiprocessing (AMP) : 비대칭 다중처리
: CPU들이 동등하게 취급되지 않음, 일부 CPU만 특정 작업을 수행할 수 있음( CPU1은 OS와 I/O 담당, CPU2~4는 계산만 수행 )
2. Symmetric multiprocessing (SMP) : 대칭 다중처리
: 모든 CPU가 동등하게 취급됨, 각각의 CPU가 독립적으로 작업 수행 가능

: Non-uniform memory access (NUMA) : 멀티프로세서 시스템에서의 메모리 설계 방식 중 하나
메모리 접근 시간이 메모리 위치에 따라 달라짐(가까우면 빠르고 멀면 느림.) , CPU마다 자기 전용 메모리를 가지고 있음
: Multi-core systems : 최근에는 한 칩 안에 여러 개의 코어를 넣는 설계
장점:
1. On-chip communication is faster (같은 칩 안의 속도는 빠르다.)
2. 전력 효율이 좋음 (전력소모가 적어)
3. 캐시 공유가 가능함 : 각 코어는 자기 캐시(local) 를 가질 수 있고, 공용 캐시(shared) 도 함께 사용 가능
: Advanced PIC (APIC) for SMP : APIC은 SMP 시스템에서 인터럽트(IRQ) 를 각 CPU에 나눠주는 역할을 하는 하드웨어
PIC의 진화
필요한 이유 : 키보드나 마우스 같은 장치에서 인터럽트가 발생하면, → 어떤 CPU가 처리할지 선택해야 함!
1. APIC : IRQ(인터럽트 요청)를 받고, 적절한 CPU를 선택해서 해당 CPU의 Local APIC으로 신호 전달
2. Local APIC (LAPIC) : 각 CPU에 하나씩 존재함, APIC에서 보낸 신호를 받아 해당 CPU에 인터럽트를 전달

'학교복습용 > 오퍼레이팅시스템 OS' 카테고리의 다른 글
| 오퍼레이팅시스템 6주차 / Processor Scheduling(9단원) (0) | 2025.04.02 |
|---|---|
| 오퍼레이팅시스템 4주차 / Process Deseription and Control(1) (0) | 2025.03.27 |
| 오퍼레이팅시스템 3주차 / Operating System Overview (1) | 2025.03.21 |
| 오퍼레이팅시스템 2주차 - (1) / Computer System Overview (0) | 2025.03.12 |
| 오퍼레이팅시스템 1주차 / Computer System Overview (0) | 2025.03.06 |