
티스토리 뷰
Memory Model
메모리 동작에 대한 규칙
1. Sequential Consistency (순차적 일관성)
가장 보수적인 모델, 명령어의 순서가 절대 바뀌지 않음. 직관적 예측가능 / 최적화 어려움, 성능저하됨.
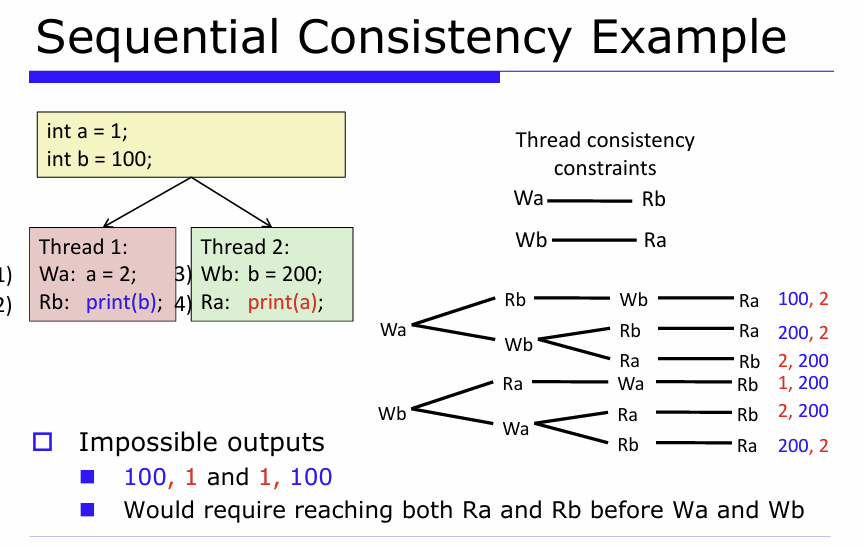
현대의 모델이 순차적 일관성을 구현하지 않는이유와 그 결과로 발생할 수 있는 문제:

메모리 베리어를 통해 명령어 순서를 보장해야 한다.
CPU나 컴파일러는 성능 향상을 위해 메모리 접근 명령을 재배열할 수 있음
→ 하지만 어떤 상황에서는 정해진 순서대로 실행되어야만 프로그램이 제대로 동작함
Memory Barrier란?: **읽기(read)와 쓰기(write)**가 원래 코드에서 작성된 순서대로 실행되도록 강제하는 특수 명령어
2. Relaxed (또는 Weaker) Consistency (완화된 일관성)
성능을 위한 모델, 명령어의 순서 재배치가 허용됨, 대신 프로그래머가 명령 순서 고정 도구를 써야 함. 최적화가 가능해 성능 향상
Memory Management
main memory의 두영역 : OS 커널 영역/ 사용자 영역
Memory Management란 : 프로세스들의 메모리 공간을 효율적으로 배분하고 관리하는 기능
페이징(Paging) 기반 메모리 관리
페이지테이블이 이 논리 페이지 번호를 물리 프레임 번호로 매핑함.
Memory management Requirements
1. relocation
프로그램이 메모리 내에서 어디에 위치할지 미리 알수 없기 때문에, 실행 중에도 다른 위치로 옮길 수 있도록 유연하게 관리해야함. 실행 중 다른 위치로 옮겨도 문제 없이 동작해야 함.
2. Protection
각 프로세스는 자신의 메모리만 접근 할 수 있어야함, 다른 프로세스의 메모리에 침범하거나 오염시키는 것 방지
메모리적재 위치를 컴파일 시간에 확인하는것은 불가능, 런타임(실행시점)에 검사되어야함.
3. sharing
메모리 공간을 효율적으로 사용하기 위해 여러 프로세스가 특정 메모리 영역(특히 코드)을 공유 할 수 있어야 한다는 의미
각 프로세스가 자신만의 복사본을 가지면 비효율적이니까 코드영역은 공유하고, 데이터는 분리
4. Logical / Physical Organization (논리/물리 구조)
프로그램이 사용하는 논리적 메모리 구조와 실제 물리적 메모리 구조는 다름.
계층형 메모리 구조 고려 필요, 보호와 공유를 논리적 수준에서 가능하게 함.
Types of Addresses
1. Symbolic Address (심볼릭 주소) – 프로그래밍 수준 : 소스코드에서 사용되는 변수 상수 라벨등
2. Relative Address (= Logical Address, Virtual Address) – 실행파일/프로세스 수준
: 프로세스의 주소 공간 내 위치, 주소공간은 항상 0부터 시작하고 컴파일타임에 가상 주소 공간에서 동작한다.
3. Absolute Address (= Physical Address) – 실제 메모리 주소
: 실제 물리 메모리상의 주소, 주소 변환 후 런타임에 절대주소로 변환된다. CPU가 RAM에 접근할 때 사용하는 주소
페이지 테이블을 통해 논리 주소의 페이지 번호를 물리 프레임 번호로 매핑
Logical Address Space
프로그램이 실행 중에 사용하는 가상의 주소 공간, 모든 프로그램은 논리적 주소0부터 시작한다. 논리주소는 실제 실행 시 물리주소로 변환 됨. 즉, 프로그램은 자신의 논리 주소를 기준으로 명령어를 fetch하고 메모리를 참조합니다.
Dynamic address Translation
런타임 중에 논리주소를 물리주소로 변환하는 과정
이 변환은 CPU + MMU등에 의해 자동으로 처리되며, 프로세스 입장에서는 투명하게 동작합니다.
0x00000088 : 논리주소 / 0x00000080 + 0x8000 : 물리 주소 = 논리 주소 + base (예: 0x8000)
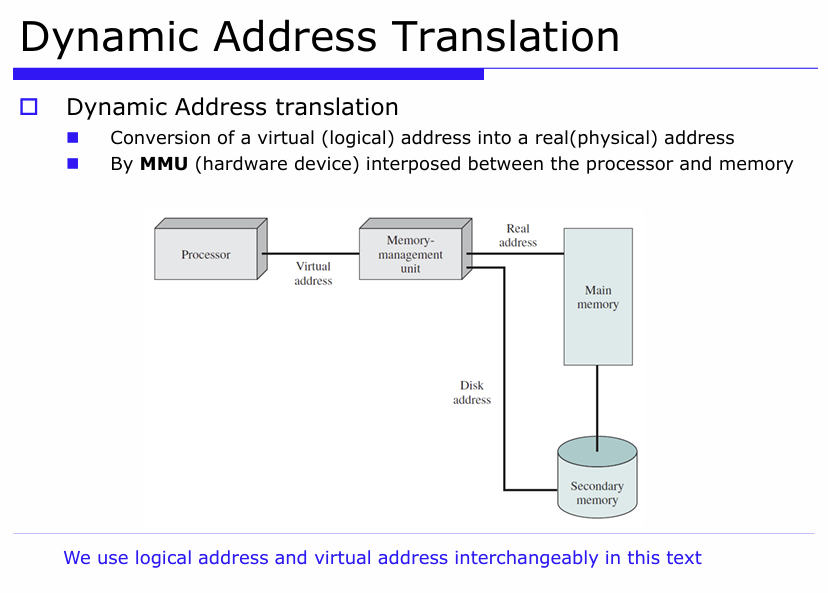
구성 요소 역할
| CPU | 논리 주소 생성 |
| MMU | 논리 주소 → 물리 주소 변환 |
| Main Memory | 변환된 주소로 접근 |
| Disk | 필요 시 page를 로드 (page fault 대응 등) |
Memory allocation
Continuous allocation(연속할당)
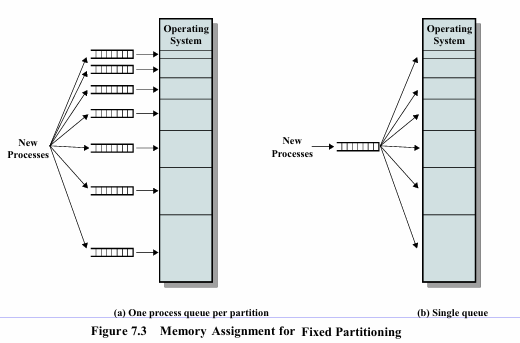
1. Fixed partitioning (고정분할방식)
- equal size
메모리를 미리정해진구역(파티션)으로 나누고, 각 파티션에 하나의 프로세스를 할당하는 방식
각 프로세스의 크기가 파티션보다 작아도 전체 파티션이 점유됨, 사용되지 않는 메모리가 남음 >> 내부단편화
장점 : 구현단순, 파티션선택무관(모두 동일한 크기), 프로세스 수용 용이
단점 : 남은공간은 낭비(내부단편화), 프로세스 수 제한( 멀티태스킹에 비효율 ), 큰 프로그램 적재 불가 (overlay)

-unequal size (비균등 고정 분할 방식)
고정분할이지만 파티션 크기는 다름.
장점 : 내부단편화 감소, 유연성 향상
단점:
두가지 할당방식:
multiple queue : 파티션별 큐 존재, 정해진 크기 구간별로 줄 서기, 단점: 특정 파티션에만 몰릴 수 있고, 유휴 공간이 생기기 쉬움
single queue: 하나의 공통 큐에 대기, 실행 가능한 파티션중 가장 작은 것 선택해서 할당

2. Dynamic partitioning (동적분할방식)
등장배경 : 남은공간은 낭비(내부단편화), 프로세스 수 제한( 멀티태스킹에 비효율 ), 큰 프로그램 적재 불가 (overlay)
특징 : 분할은 런타임에 동적으로 생성됨, 파티션 크기와 개수가 가변적, 실행 중 정확한 크기 만큼 메모리 할당
장점 : 내부단편화 없음 , 메모리 사용 효율 높음.
단점 : 외부단편화 발생, compaction비용 발생.
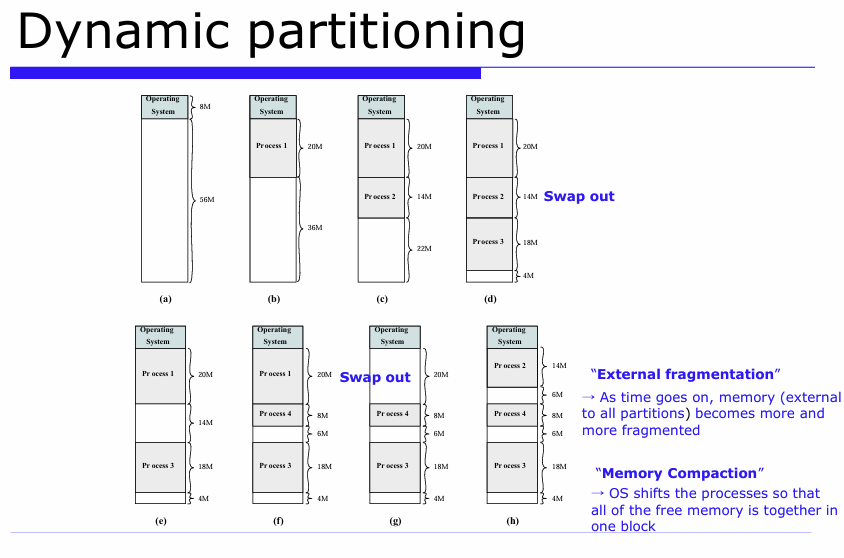
(e) swap out : 스왑아웃 (삭제됨) , 빈공간이 중간에 껴 있음 >> 외부단편화 시작
(g) process1 swap out : 하지만 이 공간은 연속되지 않아서 외부 단편화 심화
External Fragmentation (외부 단편화)
: 메모리 총 여유 공간은 충분한데, 연속된 공간이 없어 큰 프로세스를 넣지 못하는 현상
Memory Compaction (메모리 압축)
: 조각난 프로세스를 앞쪽으로 밀여 붙여 여유공간을 연속된 하나의 블록으로 만드는 작업
메모리배치전략:프로세스가 들어올 때 어느 빈 공간에 배치할 것인가?

first fit
메모리의 처음부터 스캔
next fit
이전 할당 위치부터 스캔 시작
best fit
전체블록을 조사해서 요청 크기에 가장 가까운 블록 선택
가장 느리고 단편화심화가능
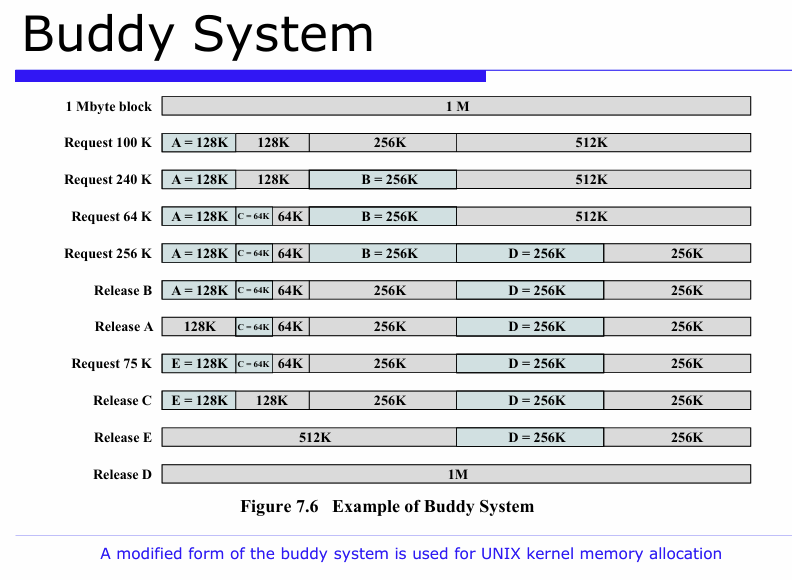
3. Buddy System (버디시스템)
동적분할방식의 외부단편화를 줄이기 위해서, 메모리 요청 시 , 2의 거듭제곱의 크기의 블록 중에서 가장 적절한 크기 블록을 분할 해서 할당
단점 : 내부단편화 존재
병합 : 반납시 짝 버디가 비어 있으면 병합
Non-continuous allocation(불연속할당)
1.Paging (분산적재) = 비연속 메모리 할당
프로세스와 메모리를 같은 크기의 조각으로 나눈 뒤, 서로 연속적이지 않아도 되는 방식으로 매핑하여 할당
| Page | 프로세스를 나눈 고정 크기 조각 |
| Frame (또는 page frame) | 메모리를 나눈 고정 크기 조각 (page와 같은 크기) |
| Page Table | 각 페이지가 어느 프레임에 매핑되었는지를 기록한 테이블 |
장점 : 외부 단편화 없음(프레임 단위로 할당하니까), 적은 내부 단편화(마지막페이지의 일부공간만 남는 정도)
주의사항 : 주소를 접근하려면 페이지번호-> 프레임 번호로 변환해야함.(주소변환비용 존재), 성능향상을 위해 TLB같은 캐시를 사용
Dynamic address translation
런타임 중에 논리주소를 물리주소로 변환하는 과정
1. page size는 반드시 2의 거듭제곱이여야 한다. : 페이지 번호와 오프셋을 쉽게 나누기 위해서
2. 논리주소 = 페이지번호 + 페이지 오프셋 ,
페이지 크기 = 2^(페이지오프) 바이트
최대로 이용할 수 있는 페이지 수 : 전체 주소공간 크기/ 페이지 크기
페이지테이블 크기 = 페이지 수 * 페이지 테이블 항목 크기

2. Segmentation (분산적재) = 비 연속 할당
주소공간을 segment로 나누고 각 세그먼트를 물리메모리에 독립적으로 매핑한다. 각 세그먼트는 크기가 다르다.
세그먼트 테이블 : 각 세그먼트의 기준주소과 크기제한을 저장함.
장점 : 내부단편화 제거 (고정크기분할방식처럼 남는 공간이 없어서 효율적)
단점 : 외부단편화 발생 (물리메모리에 빈 공간이 흩어져 있어 새로운 segment를 적절히 넣기 어려움.)
Dynamic address translation
런타임 중에 논리주소를 물리주소로 변환하는 과정
'학교복습용 > 오퍼레이팅시스템 OS' 카테고리의 다른 글
| 오퍼레이팅시스템 14주차 / 17. IO Management and Disk Scheduling (0) | 2025.06.10 |
|---|---|
| 오퍼레이팅시스템 13주차 / 16. Virtual Memory (0) | 2025.06.10 |
| 오퍼레이팅시스템 12주차 / 14. Priority Inversion and Deadlocks (0) | 2025.06.10 |
| 오퍼레이팅시스템 11주차 / 13. Condition Variables and Synchronization (3) | 2025.06.10 |
| 오퍼레이팅시스템 10주차/ 12.Mutual Exclusion and Synchronization (0) | 2025.06.05 |